TorchCode
🔥 TorchCode
Crack the PyTorch interview.
Practice implementing operators and architectures from scratch — the exact skills top ML teams test for.
An interactive coding platform, but for tensors. Self-hosted. Jupyter-based. Instant feedback.

🎯 Why TorchCode?
Top companies (Meta, Google DeepMind, OpenAI, etc.) expect ML engineers to implement core operations from memory on a whiteboard. Reading papers isn't enough — you need to write softmax, LayerNorm, MultiHeadAttention, and full Transformer blocks code.
TorchCode gives you a structured practice environment with:
| Feature | ||
|---|---|---|
| 🧩 | 40 curated problems | The most frequently asked PyTorch interview topics |
| ⚖️ | Automated judge | Correctness checks, gradient verification, and timing |
| 🎨 | Instant feedback | Colored pass/fail per test case, just like competitive programming |
| 💡 | Hints when stuck | Nudges without full spoilers |
| 📖 | Reference solutions | Study optimal implementations after your attempt |
| 📊 | Progress tracking | What you've solved, best times, and attempt counts |
| 🔄 | One-click reset | Toolbar button to reset any notebook back to its blank template — practice the same problem as many times as you want |
| Open in Colab | Every notebook has an "Open in Colab" badge + toolbar button — run problems in Google Colab with zero setup |
No cloud. No signup. No GPU needed. Just make run — or try it instantly on Hugging Face.
🚀 Quick Start
Option 0 — Try it online (zero install)
Launch on Hugging Face Spaces — opens a full JupyterLab environment in your browser. Nothing to install.
Or open any problem directly in Google Colab — every notebook has an ![]() badge.
badge.
Option 0b — Use the judge in Colab (pip)
In Google Colab, install the judge from PyPI so you can run check(...) without cloning the repo:
!pip install torch-judge
Then in a notebook cell:
from torch_judge import check, status, hint, reset_progress
status() # list all problems and your progress
check("relu") # run tests for the "relu" task
hint("relu") # show a hint
Option 1 — Pull the pre-built image (fastest)
docker run -p 8888:8888 -e PORT=8888 ghcr.io/duoan/torchcode:latest
If the registry image is unavailable for your platform, use Option 2 instead. This is the common path on Apple Silicon / arm64.
Option 2 — Build locally
make run
make run will try the prebuilt image first and automatically fall back to a local build when needed.
Open http://localhost:8888 — that's it. Works with both Docker and Podman (auto-detected).
Option 3 — Standalone Web UI (Next.js + FastAPI)
For a modern, standalone coding experience with an integrated IDE and dual-pane layout:
- Start Backend (FastAPI):
pip install -r api/requirements.txt python -m uvicorn api.main:app --port 8000 --reload - Start Frontend (Next.js):
cd web npm install npm run dev - Open http://localhost:3000 in your browser.
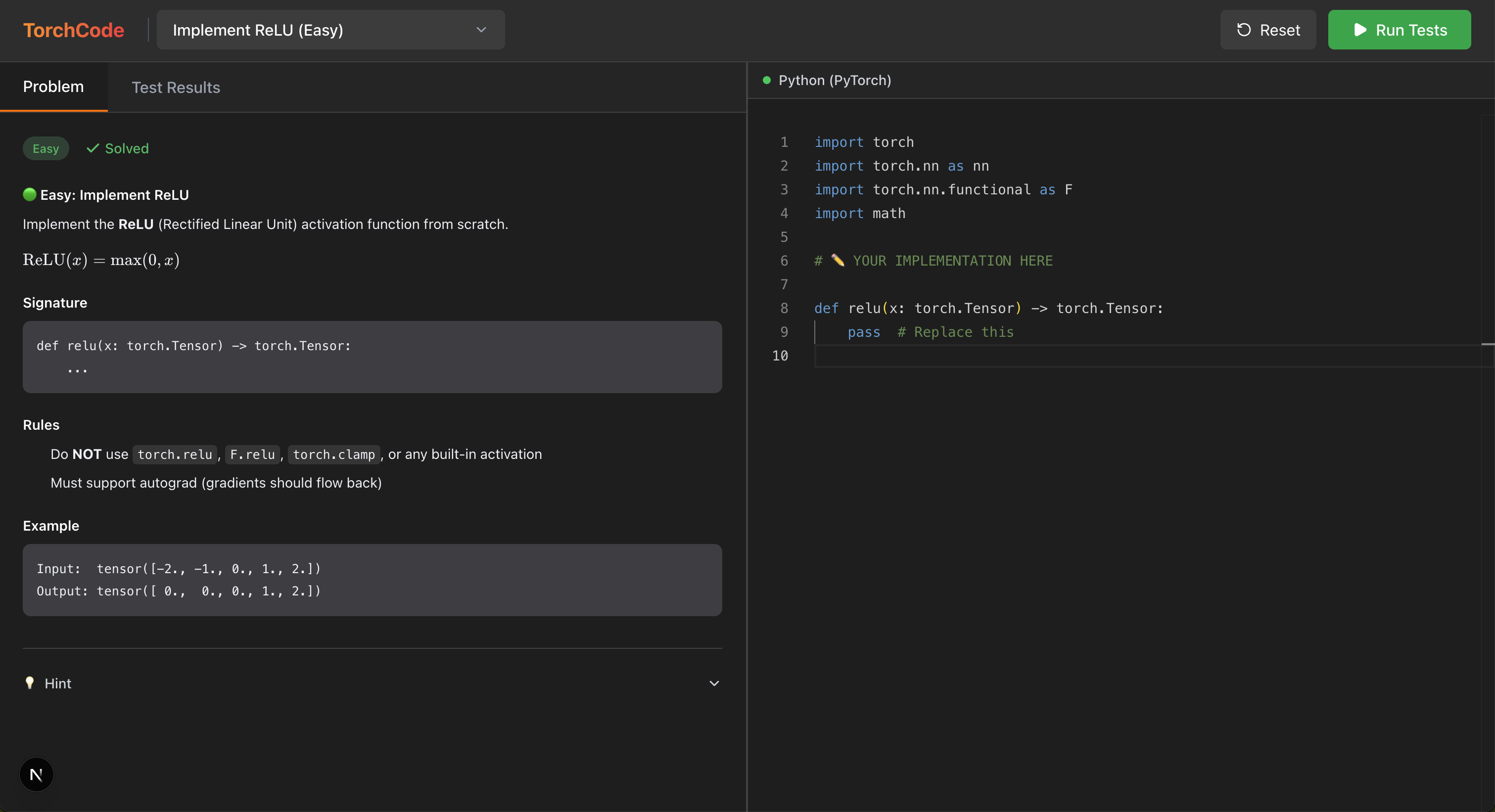
📋 Problem Set
Frequency: 🔥 = very likely in interviews, ⭐ = commonly asked, 💡 = emerging / differentiator
🧱 Fundamentals — "Implement X from scratch"
The bread and butter of ML coding interviews. You'll be asked to write these without torch.nn.
| # | Problem | What You'll Implement | Difficulty | Freq | Key Concepts |
|---|---|---|---|---|---|
| 1 | ReLU |
relu(x) |
🔥 | Activation functions, element-wise ops | |
| 2 | Softmax |
my_softmax(x, dim) |
🔥 | Numerical stability, exp/log tricks | |
| 16 | Cross-Entropy Loss |
cross_entropy_loss(logits, targets) |
🔥 | Log-softmax, logsumexp trick | |
| 17 | Dropout |
MyDropout (nn.Module) |
🔥 | Train/eval mode, inverted scaling | |
| 18 | Embedding |
MyEmbedding (nn.Module) |
🔥 | Lookup table, weight[indices] |
|
| 19 | GELU |
my_gelu(x) |
⭐ | Gaussian error linear unit, torch.erf |
|
| 20 | Kaiming Init |
kaiming_init(weight) |
⭐ | std = sqrt(2/fan_in), variance scaling |
|
| 21 | Gradient Clipping |
clip_grad_norm(params, max_norm) |
⭐ | Norm-based clipping, direction preservation | |
| 31 | Gradient Accumulation |
accumulated_step(model, opt, ...) |
💡 | Micro-batching, loss scaling | |
| 40 | Linear Regression |
LinearRegression (3 methods) |
🔥 | Normal equation, GD from scratch, nn.Linear | |
| 3 | Linear Layer |
SimpleLinear (nn.Module) |
🔥 | y = xW^T + b, Kaiming init, nn.Parameter |
|
| 4 | LayerNorm |
my_layer_norm(x, γ, β) |
🔥 | Normalization, running stats, affine transform | |
| 7 | BatchNorm |
my_batch_norm(x, γ, β) |
⭐ | Batch vs layer statistics, train/eval behavior | |
| 8 | RMSNorm |
rms_norm(x, weight) |
⭐ | LLaMA-style norm, simpler than LayerNorm | |
| 15 | SwiGLU MLP |
SwiGLUMLP (nn.Module) |
⭐ | Gated FFN, SiLU(gate) * up, LLaMA/Mistral-style |
|
| 22 | Conv2d |
my_conv2d(x, weight, ...) |
🔥 | Convolution, unfold, stride/padding |
🧠 Attention Mechanisms — The heart of modern ML interviews
If you're interviewing for any role touching LLMs or Transformers, expect at least one of these.
| # | Problem | What You'll Implement | Difficulty | Freq | Key Concepts |
|---|---|---|---|---|---|
| 23 | Cross-Attention |
MultiHeadCrossAttention (nn.Module) |
⭐ | Encoder-decoder, Q from decoder, K/V from encoder | |
| 5 | Scaled Dot-Product Attention |
scaled_dot_product_attention(Q, K, V) |
🔥 | softmax(QK^T/√d_k)V, the foundation of everything |
|
| 6 | Multi-Head Attention |
MultiHeadAttention (nn.Module) |
🔥 | Parallel heads, split/concat, projection matrices | |
| 9 | Causal Self-Attention |
causal_attention(Q, K, V) |
🔥 | Autoregressive masking with -inf, GPT-style |
|
| 10 | Grouped Query Attention |
GroupQueryAttention (nn.Module) |
⭐ | GQA (LLaMA 2), KV sharing across heads | |
| 11 | Sliding Window Attention |
sliding_window_attention(Q, K, V, w) |
⭐ | Mistral-style local attention, O(n·w) complexity | |
| 12 | Linear Attention |
linear_attention(Q, K, V) |
💡 | Kernel trick, φ(Q)(φ(K)^TV), O(n·d²) |
|
| 14 | KV Cache Attention |
KVCacheAttention (nn.Module) |
🔥 | Incremental decoding, cache K/V, prefill vs decode | |
| 24 | RoPE |
apply_rope(q, k) |
🔥 | Rotary position embedding, relative position via rotation | |
| 25 | Flash Attention |
flash_attention(Q, K, V, block_size) |
💡 | Tiled attention, online softmax, memory-efficient |
🏗️ Architecture & Adaptation — Put it all together
| # | Problem | What You'll Implement | Difficulty | Freq | Key Concepts |
|---|---|---|---|---|---|
| 26 | LoRA |
LoRALinear (nn.Module) |
⭐ | Low-rank adaptation, frozen base + BA update |
|
| 27 | ViT Patch Embedding |
PatchEmbedding (nn.Module) |
💡 | Image → patches → linear projection | |
| 13 | GPT-2 Block |
GPT2Block (nn.Module) |
⭐ | Pre-norm, causal MHA + MLP (4x, GELU), residual connections | |
| 28 | Mixture of Experts |
MixtureOfExperts (nn.Module) |
⭐ | Mixtral-style, top-k routing, expert MLPs |
⚙️ Training & Optimization
| # | Problem | What You'll Implement | Difficulty | Freq | Key Concepts |
|---|---|---|---|---|---|
| 29 | Adam Optimizer |
MyAdam |
⭐ | Momentum + RMSProp, bias correction | |
| 30 | Cosine LR Scheduler |
cosine_lr_schedule(step, ...) |
⭐ | Linear warmup + cosine annealing |
🎯 Inference & Decoding
| # | Problem | What You'll Implement | Difficulty | Freq | Key Concepts |
|---|---|---|---|---|---|
| 32 | Top-k / Top-p Sampling |
sample_top_k_top_p(logits, ...) |
🔥 | Nucleus sampling, temperature scaling | |
| 33 | Beam Search |
beam_search(log_prob_fn, ...) |
🔥 | Hypothesis expansion, pruning, eos handling | |
| 34 | Speculative Decoding |
speculative_decode(target, draft, ...) |
💡 | Accept/reject, draft model acceleration |
🔬 Advanced — Differentiators
| # | Problem | What You'll Implement | Difficulty | Freq | Key Concepts |
|---|---|---|---|---|---|
| 35 | BPE Tokenizer |
SimpleBPE |
💡 | Byte-pair encoding, merge rules, subword splits | |
| 36 | INT8 Quantization |
Int8Linear (nn.Module) |
💡 | Per-channel quantize, scale/zero-point, buffer vs param | |
| 37 | DPO Loss |
dpo_loss(chosen, rejected, ...) |
💡 | Direct preference optimization, alignment training | |
| 38 | GRPO Loss |
grpo_loss(logps, rewards, group_ids, eps) |
💡 | Group relative policy optimization, RLAIF, within-group normalized advantages | |
| 39 | PPO Loss |
ppo_loss(new_logps, old_logps, advantages, clip_ratio) |
💡 | PPO clipped surrogate loss, policy gradient, trust region |
⚙️ How It Works
Each problem has two notebooks:
| File | Purpose |
|---|---|
01_relu.ipynb |
✏️ Blank template — write your code here |
01_relu_solution.ipynb |
📖 Reference solution — check when stuck |
Workflow
1. Open a blank notebook → Read the problem description
2. Implement your solution → Use only basic PyTorch ops
3. Debug freely → print(x.shape), check gradients, etc.
4. Run the judge cell → check("relu")
5. See instant colored feedback → ✅ pass / ❌ fail per test case
6. Stuck? Get a nudge → hint("relu")
7. Review the reference solution → 01_relu_solution.ipynb
8. Click 🔄 Reset in the toolbar → Blank slate — practice again!
In-Notebook API
from torch_judge import check, hint, status
check("relu") # Judge your implementation
hint("causal_attention") # Get a hint without full spoiler
status() # Progress dashboard — solved / attempted / todo
📅 Suggested Study Plan
Total: ~12–16 hours spread across 3–4 weeks. Perfect for interview prep on a deadline.
| Week | Focus | Problems | Time |
|---|---|---|---|
| 1 | 🧱 Foundations | ReLU → Softmax → CE Loss → Dropout → Embedding → GELU → Linear → LayerNorm → BatchNorm → RMSNorm → SwiGLU MLP → Conv2d | 2–3 hrs |
| 2 | 🧠 Attention Deep Dive | SDPA → MHA → Cross-Attn → Causal → GQA → KV Cache → Sliding Window → RoPE → Linear Attn → Flash Attn | 3–4 hrs |
| 3 | 🏗️ Architecture + Training | GPT-2 Block → LoRA → MoE → ViT Patch → Adam → Cosine LR → Grad Clip → Grad Accumulation → Kaiming Init | 3–4 hrs |
| 4 | 🎯 Inference + Advanced | Top-k/p Sampling → Beam Search → Speculative Decoding → BPE → INT8 Quant → DPO Loss → GRPO Loss → PPO Loss + speed run | 3–4 hrs |
🏛️ Architecture
┌──────────────────────────────────────────┐
│ Docker / Podman Container │
│ │
│ JupyterLab (:8888) │
│ ├── templates/ (reset on each run) │
│ ├── solutions/ (reference impl) │
│ ├── torch_judge/ (auto-grading) │
│ ├── torchcode-labext (JLab plugin) │
│ │ 🔄 Reset — restore template │
│ │ 🔗 Colab — open in Colab │
│ └── PyTorch (CPU), NumPy │
│ │
│ Judge checks: │
│ ✓ Output correctness (allclose) │
│ ✓ Gradient flow (autograd) │
│ ✓ Shape consistency │
│ ✓ Edge cases & numerical stability │
└──────────────────────────────────────────┘
Single container. Single port. No database. No frontend framework. No GPU.
🛠️ Commands
make run # Build & start (http://localhost:8888)
make stop # Stop the container
make clean # Stop + remove volumes + reset all progress
🧩 Adding Your Own Problems
TorchCode uses auto-discovery — just drop a new file in torch_judge/tasks/:
TASK = {
"id": "my_task",
"title": "My Custom Problem",
"difficulty": "medium",
"function_name": "my_function",
"hint": "Think about broadcasting...",
"tests": [ ... ],
}
No registration needed. The judge picks it up automatically.
📦 Publishing torch-judge to PyPI (maintainers)
The judge is published as a separate package so Colab/users can pip install torch-judge without cloning the repo.
Automatic (GitHub Action)
Pushing to master after changing the package version triggers .github/workflows/pypi-publish.yml, which builds and uploads to PyPI. No git tag is required.
- Bump version in
torch_judge/_version.py(e.g.__version__ = "0.1.1"). - Configure PyPI Trusted Publisher (one-time):
- PyPI → Your project torch-judge → Publishing → Add a new pending publisher
- Owner:
duoan, Repository:TorchCode, Workflow:pypi-publish.yml, Environment: (leave empty) - Run the workflow once (push a version bump to
masteror Actions → Publish torch-judge to PyPI → Run workflow); PyPI will then link the publisher.
- Release: commit the version bump and
git push origin master.
Alternatively, use an API token: add repository secret PYPI_API_TOKEN (value = pypi-... from PyPI) and set TWINE_USERNAME=__token__ and TWINE_PASSWORD from that secret in the workflow if you prefer not to use Trusted Publishing.
Manual
pip install build twine
python -m build
twine upload dist/*
Version is in torch_judge/_version.py; bump it before each release.
❓ FAQ
Do I need a GPU?
No. Everything runs on CPU. The problems test correctness and understanding, not throughput.
Can I keep my solutions between runs?
Blank templates reset on every
make run so you practice from scratch. Save your work under a different filename if you want to keep it. You can also click the 🔄 Reset button in the notebook toolbar at any time to restore the blank template without restarting.
Can I use Google Colab instead?
Yes! Every notebook has an Open in Colab badge at the top. Click it to open the problem directly in Google Colab — no Docker or local setup needed. You can also use the Colab toolbar button inside JupyterLab.
How are solutions graded?
The judge runs your function against multiple test cases using
torch.allclose for numerical correctness, verifies gradients flow properly via autograd, and checks edge cases specific to each operation.
Who is this for?
Anyone preparing for ML/AI engineering interviews at top tech companies, or anyone who wants to deeply understand how PyTorch operations work under the hood.
🤝 Contributors
Thanks to everyone who has contributed to TorchCode.

duoan |

Ando233 |

abhijitmjj |

HareshKarnan |

ThierryHJ |
Auto-generated from the GitHub contributors graph with avatars and GitHub usernames.
Built for engineers who want to deeply understand what they build.
If this helped your interview prep, consider giving it a ⭐
☕ Buy Me a Coffee
![]()

Scan to support
